
Philippians 4:13
FDN: A Real-Time Ensemble FireDetection Network 본문
*요약
FDN: A Real-Time Ensemble FireDetection Network에 대한 해당 페이지의 주요 내용은 다음과 같습니다.
FDN 개요
- FDN(FireDetection Network)은 실시간 화재 감지를 위해 제안된 앙상블 기반 딥러닝 네트워크입니다.
- 기존의 화재 감지 모델들이 놓치는 다양한 화재 상황을 더 정확하게 탐지하기 위해 여러 모델의 장점을 결합한 것이 특징입니다.
주요 특징
- 앙상블 구조: FDN은 여러 개의 베이스 모델(예: YOLO, EfficientNet 등)을 조합하여 각 모델의 예측 결과를 통합합니다
- 실시간 처리: 모델 경량화 및 최적화를 통해 CCTV 등 실시간 영상에서도 빠르게 화재를 감지할 수 있습니다.
- 정확도 향상: 다양한 화재 상황(연기, 불꽃, 다양한 조명 조건 등)에서 높은 탐지 성능을 보입니다.
성능 및 실험 결과
- FDN은 기존 단일 모델 대비 화재 탐지 정확도(Precision, Recall, F1 Score 등)에서 우수한 성능을 보였습니다.
- 실제 화재 영상 데이터셋을 활용한 실험에서 높은 실시간 처리 속도와 정확도를 동시에 달성했습니다.
결론
- FDN은 실시간 환경에서의 신속하고 정확한 화재 감지에 적합한 모델로, CCTV, 산업 현장 등 다양한 응용 분야에 활용될 수 있습니다.
이 요약은 해당 페이지의 주요 내용을 기반으로 작성되었습니다.
ABSTRACT
Fires frequently occur worldwide, devastating neighborhoods and forests owing to challenges
in early extinguishment. Computer vision-based deep learning models have recently been employed in fire
detection research. The primary objective of this study is to develop a multiclass fire detection model using
images and videos. In this study, an ensemble fire detection model, FireDetectNet (FDN), comprising several
classification models (ResNeXt-50 (32x4d), EfficinetNet-B4) and one object detection model (Yolov5) is
proposed. This model classifies fire and three different colors of smoke, fog, light, and sunlight. The training
of multiple as an ensemble results in their performance being superior to that of a single classification or
detection model. In the classification phase, our model (FDN) achieves an F1-score that is 11.3% higher
than that of the single-classification model and 31.7% higher specifically for gray smoke. In the detection
phase, mAP@50 and mAP@50:95 are improved by 1.3% and 1.6%, respectively, compared to the single
detection model, Yolov5s. The proposed model effectively distinguishes between fog and clouds, similar to
smoke, and light and sunlight, akin to a real fire using the Partial-Loss-Balanced TaskWeighting (P-LBTW)
algorithm we develop to reduce negative transfer by partially learning task-specific weights. Leveraging the
classified and detected results, wildfires can be promptly and accurately identified wherever the equipment
is deployed, thus mitigating the risk of large-scale fires. Therefore, the proposed real-time ensemble fire
detection system offers practical models and system configurations for field deployment, facilitating early
fire suppression to mitigate fire damage.
화재는 전 세계적으로 빈번하게 발생하며, 조기 진화의 어려움으로 인해 지역 사회와 산림이 파괴되고 있습니다.
최근 컴퓨터 비전 기반 딥러닝 모델이 화재 감지 연구에 활용되고 있습니다.
본 연구의 주요 목표는 이미지와 비디오를 활용하여 다중 클래스 화재 감지 모델을 개발하는 것입니다.
본 연구에서는 여러 분류 모델(ResNeXt-50(32x4d), EfficinetNet-B4)과 하나의 객체 감지 모델(Yolov5)로 구성된 앙상블 화재 감지 모델인 FireDetectNet(FDN)을 제안합니다.
이 모델은 화재와 세 가지 다른 색상의 연기, 안개, 빛, 햇빛을 분류합니다.
여러 모델을 앙상블 방식으로 학습시키면 단일 분류 또는 감지 모델보다 성능이 우수합니다.
분류 단계에서 본 모델(FDN)은 단일 분류 모델보다 11.3% 높은 F1 점수를 달성하며, 특히 회색 연기에 대해서는 31.7% 더 높은 점수를 달성합니다.
탐지 단계에서 mAP@50과 mAP@50:95는 단일 탐지 모델인 Yolov5s에 비해 각각 1.3%와 1.6% 향상되었습니다.
제안된 모델은 작업별 가중치를 부분적으로 학습하여 부정적 전이를 줄이기 위해 개발한 부분 손실 균형 작업 가중치(P-LBTW) 알고리즘을 사용하여 연기처럼 안개와 구름, 실제 화재처럼 빛과 햇빛을 효과적으로 구분합니다.
분류 및 탐지된 결과를 활용하여 장비가 배치된 모든 곳에서 산불을 신속하고 정확하게 식별하여 대규모 화재 위험을 완화할 수 있습니다.
따라서 제안된 실시간 앙상블 화재 탐지 시스템은 현장 배치를 위한 실용적인 모델과 시스템 구성을 제공하여 화재 피해를 완화하기 위한 조기 화재 진압을 용이하게 합니다.
INDEX TERMS
Wildfire, Fire and smoke detection, Deep learning, Ensemble Detection Framework, Multilabel classification, Partial-Loss-Balanced Task Weighting (P-LBTW)
I. INTRODUCTION
A fire is a devastating natural disaster that is unpredictable in terms of where and when it occurs. Fires cause loss of life,
property, and socioeconomic damage. Fires that occur in the wild, such as in forests, may develop into large-scale fires
and cause significant environmental damage worldwide [1]. Recently, a large wildfire occurred in South Korea, causing
damage to 379 ha [2]. Therefore, if an economical real-time fire detection system detects the initial fire and smoke, the
damage caused by the fire can be minimized. With recent technological advancements, computer vision-based fire detection algorithms have exhibited high performance in detecting fires [3]. However, artificial intelligence models that distinguish fire and smoke are plagued by certain problems. First, a training dataset can be built based on ground-truth
values up to a certain limit. When using videos and images from actual fire sites as training datasets, achieving high
accuracy and precision is challenging because of problems with labeling and data quality during preprocessing. In the
data collected from various locations in [4], the entire image is a fire, or the fire and smoke overlap in such a way that
it is difficult to distinguish between them, resulting in the inaccurate learning of each class. Second, the number of
classes is limited and biased.
화재는 발생 장소와 시기를 예측할 수 없는 파괴적인 자연재해입니다. 화재는 인명 피해, 재산 피해, 그리고 사회경제적 피해를 초래합니다. 산림과 같은 자연에서 발생하는 화재는 대규모 화재로 발전하여 전 세계적으로 심각한 환경 피해를 초래할 수 있습니다[1].
최근 한국에서 발생한 대형 산불로 379ha의 피해가 발생했습니다[2]. 따라서 경제적인 실시간 화재 감지 시스템이 초기 화재와 연기를 감지한다면 화재로 인한 피해를 최소화할 수 있습니다. 최근 기술 발전으로 컴퓨터 비전 기반 화재 감지 알고리즘이 화재 감지에 높은 성능을 보였습니다[3]. 그러나 화재와 연기를 구분하는 인공지능 모델은 특정 문제에 직면해 있습니다.
첫째, 특정 한계까지의 지상 진실(ground-truth) 값을 기반으로 훈련 데이터셋을 구축할 수 있습니다. 실제 화재 현장의 비디오와 이미지를 학습 데이터셋으로 사용할 경우, 전처리 과정에서 레이블 지정 및 데이터 품질 문제로 인해 높은 정확도와 정밀도를 달성하는 것이 어렵습니다. [4]에서 다양한 위치에서 수집한 데이터에서는 이미지 전체가 화재이거나, 화재와 연기가 겹쳐 구분하기 어려워 각 클래스의 학습이 부정확합니다. 둘째, 클래스 수가 제한적이고 편향되어 있습니다.

In [4] and [5], where there are three classes: fire, smoke, and ‘Other,’ only fire and smoke are annotated with labels,
and the other objects are classified as ‘None.’ Even if the other objects have labels,
they are not broken down and categorized separately; instead, they are all categorized together
as ‘Other.’ Consequently, this approach fails to distinguish between objects or lights that appear similar to fire, and
it also does not differentiate between fog and clouds that resemble smoke. Existing datasets often lack annotations for
all scenarios in natural fire scenes, thus failing to capture all the characteristics of such scenes. Therefore, most datasets
demonstrate accuracy that is only satisfactory within a specific class. Notably, in the dataset of studies that attempted to
approach classification and detection based on deep learning, only fire and smoke were presented in [6], [7], and [8];
however, fog or clouds, which resemble smoke, were not distinguished. In particular, in [6], there are experiments
related to weather, but they do not refer to the detection of simple fog, but to detecting fire when the weather condition
is fog. [9] did not correctly distinguish between fog and clouds and classified them vaguely, such as ‘like_smoke.’
[10] constructed a network using a convolutional neural network (CNN) by building a satellite image dataset.
[4]와 [5]에서는 화재, 연기, '기타'의 세 가지 클래스가 있으며, 화재와 연기에만 레이블이 지정되고 다른 객체는 '없음'으로 분류됩니다. 다른 객체에 레이블이 있더라도 별도로 분류되지 않고 모두 '기타'로 함께 분류됩니다. 결과적으로 이 접근 방식은 화재와 유사한 객체나 조명을 구분하지 못하고, 안개와 연기와 유사한 구름도 구분하지 못합니다. 기존 데이터 세트는 자연 화재 장면의 모든 시나리오에 대한 주석이 부족하여 이러한 장면의 모든 특성을 포착하지 못하는 경우가 많습니다. 따라서 대부분의 데이터 세트는 특정 클래스 내에서만 만족스러운 정확도를 보입니다. 특히 딥 러닝 기반 분류 및 탐지를 시도한 연구의 데이터 세트에서는 화재와 연기만 제시되었지만, 연기와 유사한 안개나 구름은 구분하지 못했습니다. 특히 [6]에는 날씨와 관련된 실험이 있지만, 단순한 안개 감지가 아니라 날씨가 안개일 때 화재를 감지하는 것에 대한 것입니다. [9]는 안개와 구름을 정확하게 구분하지 못하고 'like_smoke'와 같이 모호하게 분류했습니다. [10]은 위성 이미지 데이터셋을 구축하여 합성곱 신경망(CNN)을 이용한 네트워크를 구축했습니다.
However, in terms of methods, experimental results have been derived using either a single object detection model
[11] or by employing ensemble methods such as bagging and boosting [12], [13], incorporating several object detection
models [10]. Among the ensemble methods, [14] proposed a hybrid method by combining several CNN-based classification models with Support Vector Machine, Random Forest, Bidirectional Long Short-Term Memory, and Gated Recurrent Unit algorithms. [15] employed two object detection models (Yolov5 and EfficientDet)
in an ensemble alongside a single classification model (EfficientNet) to detect fires of various sizes.
[16] used segmentation for detecting fire and smoke, while [17] employed sequence-to-sequence
prediction for fire images using transformers, which were neither feature-based nor deep learning-based.
[18] used YOLO-based models to detect indoor, building, and vehicle fires,
whereas [19] utilized an ensemble method employing ResNet-based models for binary results. Moreover, current
deep learning-based methods for fire detection do not focus on the region proposal stage, but consider it as a fire or
non-fire classification task [16], [17], [19]. These methods consider the whole image as one class and often fires or
smoke occupy only a small region of the image. Therefore, in this paper, we propose the FireDetectNet (FDN), which
emphasizes the region proposal stage along with the classification module.
그러나 방법론 측면에서 실험 결과는 단일 객체 탐지 모델[11]을 사용하거나 배깅 및 부스팅[12], [13]과 같은 앙상블 방법을 사용하여 도출되었으며, 여기에는 여러 객체 탐지 모델[10]이 통합되어 있습니다. 앙상블 방법 중 [14]는 여러 CNN 기반 분류 모델과 지원 벡터 머신, 랜덤 포레스트, 양방향 LSTM(Long Short-Term Memory), 게이트 순환 유닛(Gated Recurrent Unit) 알고리즘을 결합한 하이브리드 방법을 제안했습니다. [15]는 단일 분류 모델(EfficientNet)과 함께 앙상블에서 두 가지 객체 탐지 모델(Yolov5 및 EfficientDet)을 사용하여 다양한 규모의 화재를 탐지했습니다. [16]은 화재 및 연기 탐지를 위해 분할을 사용했고, [17]은 특징 기반도 아니고 딥 러닝 기반도 아닌 변환기를 사용하여 화재 이미지에 대한 시퀀스 간 예측을 사용했습니다. [18]은 실내, 건물 및 차량 화재를 감지하기 위해 YOLO 기반 모델을 사용했고, [19]는 이진 결과에 ResNet 기반 모델을 사용하는 앙상블 방법을 활용했습니다. 더욱이, 현재의 화재 감지를 위한 딥러닝 기반 방법들은 영역 제안 단계에 초점을 맞추지 않고 이를 화재 또는 비화재 분류 작업으로 간주합니다[16], [17], [19]. 이러한 방법들은 전체 이미지를 하나의 클래스로 간주하며, 화재 또는 연기는 종종 이미지의 작은 영역만 차지합니다. 따라서 본 논문에서는 분류 모듈과 함께 영역 제안 단계를 강조하는 FireDetectNet(FDN)을 제안합니다.
However, the studies mentioned above were not optimized for achieving high accuracy for a fast response, as they did
not focus on the classification of fire, smoke, clouds, and fog. This study proposes an ensemble method that categorizes
data into eight classes: black smoke, gray smoke, white smoke, fog, clouds, light, sunlight, and flames(fire).
Our model FDN conducts both classification and detection tasks simultaneously. In FDN, there are classification and
detection phases, and a layer fuses each phase’s results. In the classification phase, the accuracy of multi-class is high,
but localization of each object cannot be performed, and in the detection phase, the accuracy of classification is low
compared to the classification phase, but localization can be performed. Therefore, unlike state-of-the-art models, FDN
can achieve improved performance by fusing the results of multi-class label information in the classification phase and
localization information in the detection phase. It accurately classifies images by dividing them into eight types instead of
simply two classes(fire or non-fire).
This study proposes an ensemble model that classifies and detects black/gray/white smoke, fire(flame), fog, cloud,
light, and sunlight. Experiments show that the classification performance of the proposed ensemble model is superior
to that of individual classification models. Each class value is derived using several classification models configured in
parallel for the same image. Simultaneously, the final class is determined by reflecting the results from
the object detection model in the decision strategy. If an economical real-time fire detection system can detect
early stage fires effectively and subsequently predict the scale of fires, it can contribute to minimizing fire damage.
This study aims to compare and analyze ensemble models to overcome the limitations of actual
fire classification and prediction models due to the various causes and characteristics of fires.
Thus, domain experts can select and utilize the best single classification model or highly effective ensemble model based on the domain in the field. The primary contributions and novelties of this study are as follows:
그러나 위에서 언급한 연구들은 화재, 연기, 구름, 안개 분류에 초점을 맞추지 않았기 때문에 빠른 대응을 위한 높은 정확도를 달성하도록 최적화되지 않았습니다. 본 연구는 데이터를 검은 연기, 회색 연기, 흰 연기, 안개, 구름, 빛, 햇빛, 그리고 불꽃(화재)의 8가지 클래스로 분류하는 앙상블 방법을 제안합니다.
본 연구에서 제안하는 모델인 FDN은 분류와 탐지 작업을 동시에 수행합니다. FDN에는 분류 및 탐지 단계가 있으며, 각 단계의 결과를 하나의 레이어로 통합합니다. 분류 단계에서는 다중 클래스의 정확도는 높지만 각 객체의 위치 추정은 불가능하고, 탐지 단계에서는 분류 단계보다 분류 정확도는 낮지만 위치 추정은 가능합니다. 따라서 최신 모델과 달리 FDN은 분류 단계에서 다중 클래스 레이블 정보의 결과와 탐지 단계에서 위치 추정 정보를 통합하여 향상된 성능을 얻을 수 있습니다. 이미지를 단순히 두 가지 클래스(화재 또는 비화재)로 구분하는 대신 8가지 유형으로 구분하여 정확하게 분류합니다.
본 연구는 흑색/회색/백색 연기, 화염, 안개, 구름, 빛, 햇빛을 분류하고 감지하는 앙상블 모델을 제안합니다. 실험 결과, 제안된 앙상블 모델의 분류 성능이 개별 분류 모델보다 우수함을 보여줍니다. 각 클래스 값은 동일한 이미지에 대해 병렬로 구성된 여러 분류 모델을 사용하여 도출됩니다. 동시에 객체 감지 모델의 결과를 의사 결정 전략에 반영하여 최종 클래스를 결정합니다. 경제적인 실시간 화재 감지 시스템이 화재 초기 단계의 화재를 효과적으로 감지하고 화재 규모를 예측할 수 있다면 화재 피해를 최소화하는 데 기여할 수 있습니다.
본 연구는 화재의 다양한 원인과 특성으로 인한 실제 화재 분류 및 예측 모델의 한계를 극복하기 위해 앙상블 모델을 비교 분석하는 것을 목표로 합니다.
따라서 도메인 전문가는 해당 분야의 도메인에 따라 최적의 단일 분류 모델 또는 매우 효과적인 앙상블 모델을 선택하고 활용할 수 있습니다. 본 연구의 주요 기여도와 새로운 점은 다음과 같습니다.
• We propose a CNN framework optimized for fire detection. The FireDetectNet (FDN) framework performs
both fire classification and detection simultaneously.
• In the Detection module of FDN, Yolov5 [21] is utilized. While the original Yolov5 is pre-trained with 80
labels, we customize it to detect eight specific classes optimized for fire detection, including fog, cloud, and
smoke of various colors, such as black, gray, and white. We conduct end-to-end training rather than fine-tuning,
thereby achieving a higher mean average precision (AP) performance of up to 4.3%.
• The Classification module of FDN employs two head modules from the state-of-the-art models (ResNeXt-
50(32x4d) and EfficientNet-B4) to classify images into a total of eight classes. We utilize multi-label classification
to address the high error rates when classifying images containing both smoke and fire as a single class
in multi-class classification. Consequently, the proposed model improves the performance of the F1-score to a
maximum of 34.4%.
• We also propose a multi-task weighting method, Partial- Loss-Balanced Task Weighting (P-LBTW). P-LBTW
reduces negative transfer and improves overall performance by partially learning task-specific weights in
FDN.
• 화재 감지에 최적화된 CNN 프레임워크를 제안합니다. FireDetectNet(FDN) 프레임워크는 화재 분류와 감지를 동시에 수행합니다.
• FDN의 감지 모듈에서는 Yolov5[21]를 사용합니다. 기존 Yolov5는 80개의 레이블로 사전 학습되었지만, 본 연구에서는 안개, 구름, 검정, 회색, 흰색 등 다양한 색상의 연기 등 화재 감지에 최적화된 8개의 특정 클래스를 감지하도록 맞춤 설정했습니다. 미세 조정 대신 종단 간 학습을 수행하여 최대 4.3%의 높은 평균 정밀도(AP) 성능을 달성했습니다.
• FDN의 분류 모듈은 최첨단 모델(ResNeXt-50(32x4d) 및 EfficientNet-B4)의 두 헤드 모듈을 사용하여 이미지를 총 8개의 클래스로 분류합니다. 다중 클래스 분류에서 연기와 화재가 모두 포함된 이미지를 단일 클래스로 분류할 때 발생하는 높은 오류율을 해결하기 위해 다중 레이블 분류를 사용합니다. 결과적으로, 제안된 모델은 F1 점수의 성능을 최대 34.4%까지 향상시킵니다.
• 또한 다중 작업 가중치 부여 방법인 부분 손실 균형 작업 가중치(P-LBTW)를 제안합니다. P-LBTW는 FDN에서 작업별 가중치를 부분적으로 학습하여 부정 전이를 줄이고 전반적인 성능을 향상시킵니다.
TABLE 1. Raw dataset from AI-Hub [20].

The remainder of this paper is organized as follows.Section II reviews the related literature on fire and smoke
detection. Section III describes the dataset built in this study and presents a visualization. Further, it provides a detailed
explanation of the proposed method, FDN. In Section IV, we compare the performance of individual models and FDN
as an ensemble model and present the results for subclasses. Sections V and VI discuss and conclude the paper, respectively.
본 논문의 나머지 부분은 다음과 같이 구성됩니다. II절에서는 화재 및 연기 감지 관련 문헌을 검토합니다. III절에서는 본 연구에서 구축된 데이터셋을 설명하고 시각화를 제시합니다. 또한, 제안하는 방법인 FDN에 대해 자세히 설명합니다. IV절에서는 개별 모델과 앙상블 모델로서 FDN의 성능을 비교하고 하위 클래스별 결과를 제시합니다. V절과 VI절에서는 각각 본 논문에 대해 논의하고 결론을 맺습니다.
II. LITERATURE REVIEW
II. 문헌 검토
Wildfires are critical phenomena that must be detected early.
Therefore, studies have been conducted to detect outdoor fires, such as wildfires, or forest fires. Research on fire
or smoke detection is primarily undertaken through two frameworks: sensor-based and computer vision-based fire
and smoke detection frameworks.
산불은 조기에 감지해야 하는 중요한 현상입니다.
따라서 산불이나 산불과 같은 실외 화재를 감지하기 위한 연구가 진행되어 왔습니다. 화재 또는 연기 감지 연구는 주로 센서 기반 및 컴퓨터 비전 기반 화재 및 연기 감지 프레임워크라는 두 가지 프레임워크를 통해 수행됩니다.
A. SENSOR-BASED FEATURES
The early sensor-based technology essentially involved the development of heat/smoke/flame sensors [22]
or gas sensors [23], which played an essential role in minimizing losses by detecting fires at an early stage.
These sensors are activated when they detect particles from a fire. While they work well in small indoor
spaces and have high accuracy, they are unsuitable for point sensors in open spaces because the
particles must pass through more paths [24]. Detection using sensors, as demonstrated in [25], is later analyzed using heatmaps.
B. VISION-BASED FEATURES
B. 비전 기반 특징
Computer vision-based features are used in vision-based frameworks. In computer vision-based frameworks, static
features such as the color of fire and smoke [26]–[28], wavelets [29], energy [30], texture [31], [32], and irregularity
[32] are utilized. The detection of fire or smoke, which can be considered as moving objects, primarily uses background
subtraction methods [33], [34], temporal differencing [35], and optical flow estimation [36]. Classification uses background
subtraction methods to select the area of interest and extract moving features by employing detection methods
such as optical flow. These extracted features perform smoke classification using a classifier such as SVM [29].
Furthermore, [28] and [31] employed thresholds or parameters for fire smoke classification, which is less time-consuming but may be unsuitable for complex environments. Once these features were extracted, [32], [31], and [37] employed a
Support Vector Machine (SVM) classifiers, while [30] used a Bayesian algorithm for a simple binary classification of fire
or smoke.
Recently, fire and smoke classification and detection methods have used deep-learning models based on CNNs. [38]
proposed a new hybrid method for detecting the smoke. They employed a CNN-based motion detection scheme to extract deep, spatial and spatio-temporal features of each smokelike regions, and SVM was used for smoke
detection. [39] applied a modified soft attention mechanism to extract key areas of fire or smoke in the images.
The detection models can be categorized into two types: one-stage and two-stage
detectors. The two-stage detector performs object detection in two separate stages. The first stage recommends areas
where objects may be present(Region Proposal), whereas the second stage comprehensively analyzes those areas to
predict the location(bounding box regression) and class of the object(classifying the classes of images). Examples of
two-stage detectors include Regions with CNNs (R-CNN)[40], spatial pyramid pooling network (SPP-Net) [41], mask R-CNN [42], fast R-CNN [43], faster R-CNN [44], feature pyramid networks (FPN) [45], cascade R-CNN [46], and
deformable transformers for end-to-end object detection (Deformable DETR) [47].
컴퓨터 비전 기반 특징은 비전 기반 프레임워크에서 사용됩니다. 컴퓨터 비전 기반 프레임워크에서는 불과 연기의 색상[26]–[28], 웨이블릿[29], 에너지[30], 질감[31], [32], 불규칙성[32]과 같은 정적 특징이 활용됩니다. 움직이는 물체로 간주될 수 있는 화재나 연기의 감지에는 주로 배경 차감법[33], [34], 시간 차분법[35], 광 흐름 추정법[36]이 사용됩니다. 분류에서는 배경 차감법을 사용하여 관심 영역을 선택하고 광 흐름과 같은 감지 방법을 사용하여 움직이는 특징을 추출합니다. 이렇게 추출된 특징은 SVM[29]과 같은 분류기를 사용하여 연기 분류를 수행합니다.
또한, [28]과 [31]은 화재/연기 분류를 위해 임계값 또는 매개변수를 사용했는데, 이는 시간이 덜 소요되지만 복잡한 환경에는 적합하지 않을 수 있습니다. 이러한 특징이 추출된 후, [32], [31], [37]은 지원 벡터 머신(SVM) 분류기를 사용했고, [30]은 화재 또는 연기의 단순 이진 분류를 위해 베이지안 알고리즘을 사용했습니다.
최근 화재 및 연기 분류 및 감지 방법에 CNN 기반 딥러닝 모델이 사용되었습니다. [38]은 연기 감지를 위한 새로운 하이브리드 방법을 제안했습니다. CNN 기반 동작 감지 방식을 사용하여 각 연기 유사 영역의 심층적, 공간적 및 시공간적 특징을 추출했으며, SVM을 연기 감지에 사용했습니다. [39]는 수정된 소프트 어텐션 메커니즘을 적용하여 이미지에서 화재 또는 연기의 주요 영역을 추출했습니다.
감지 모델은 1단계 감지기와 2단계 감지기의 두 가지 유형으로 분류할 수 있습니다.
2단계 감지기는 두 개의 별도 단계로 객체 감지를 수행합니다. 첫 번째 단계는 객체가 존재할 수 있는 영역을 추천하는 반면(Region Proposal), 두 번째 단계는 해당 영역을 종합적으로 분석하여 객체의 위치(Bounding Box Regression)와 클래스(이미지 클래스 분류)를 예측합니다.
2단계 검출기의 예로는 CNN을 사용한 영역(R-CNN)[40], 공간 피라미드 풀링 네트워크(SPP-Net)[41], 마스크 R-CNN[42], 고속 R-CNN[43], 고속 R-CNN[44], 특징 피라미드 네트워크(FPN)[45], 캐스케이드 R-CNN[46], 그리고 종단 간 객체 감지를 위한 변형 가능 변환기(Deformable DETR)[47]가 있습니다.

One-stage detectors such as Yolov5 have been developed and released. In contrast to two-stage detectors, the region
proposal and classification parts are integrated into a onestage detector in one step. Representative examples include
the single shot multibox detector (SSD) [48]), Yolov1-5 [49]–[52], RetinaNet [53], CenterNet [54], and EfficientDet [55].
One-stage detectors with state-of-the-art performance have been actively used in the field of fire detection [15], [56].
Recent advancements in transformer-based object detection have significantly contributed to the field. [57] explores
transformer-based approaches for few-shot object detection and instance segmentation, while [58] combines Swin
Transformers with YOLO architectures to improve detection performance. Additionally, [59] introduces a transformer
model that reduces computational costs for event-based detection while maintaining high accuracy. In parallel, multitask
learning-based models have drawn significant interest, offering solutions that handle multiple detection
tasks simultaneously.
[60] incorporates knowledge distillation strategies to enhance performance in few-shot detection scenarios, and
[61] presented a YOLO-based multi-head model designed for efficient multi-task detection.
These advancements highlight the growing importance of both transformer-based and multitask learning approaches,
particularly in specialized applications such as fire detection, where both accurate classification and detection are critical.
The proposed ensemble model involves crucial differentiation from two perspectives. The first perspective involves the
classification of smoke, fog, cloud, fire, light, and sunlight by training a model with data that includes not only fire and
smoke but also features similar to smoke such as "fogs" and "clouds," as well as features akin to fire like
"light," and "sunlight". Second, rather than relying on just one deep learning model, several classification models
such as ResNeXt-50 and EfficientNet-B4 are constructed in parallel to classify images
simultaneously and extract situational descriptions using Yolov5, a powerful object detection model. Subsequently,
the classified images and detected objects are simultaneously trained to the ensemble model to maximize the efficiency
of classification and detection, thereby improving overall performance.
Yolov5와 같은 1단계 검출기가 개발되어 출시되었습니다. 2단계 검출기와 달리 영역 제안 및 분류 부분이 1단계 검출기에 한 단계로 통합됩니다. 대표적인 예로는
단일 샷 멀티박스 검출기(SSD) [48], Yolov1-5 [49]–[52], RetinaNet [53], CenterNet [54], EfficientDet [55]가 있습니다.
최첨단 성능을 갖춘 1단계 검출기는 화재 감지 분야에서 활발하게 사용되고 있습니다 [15], [56].
변환기 기반 객체 감지의 최근 발전은 이 분야에 크게 기여했습니다. [57]은
소샷 객체 감지 및 인스턴스 분할을 위한 변환기 기반 접근 방식을 탐구하는 반면, [58]은 Swin 변환기를 YOLO 아키텍처와 결합하여 감지 성능을 향상시킵니다. 또한, [59]는 높은 정확도를 유지하면서 이벤트 기반 감지의 계산 비용을 줄이는 변환기 모델을 소개합니다. 동시에, 멀티태스크 학습 기반 모델은 여러 감지 작업을 동시에 처리하는 솔루션을 제공하면서 상당한 관심을 불러일으켰습니다.
[60]은 소수 감지 시나리오에서 성능을 향상시키기 위해 지식 증류 전략을 통합했으며,
[61]은 효율적인 멀티태스크 감지를 위해 설계된 YOLO 기반 멀티헤드 모델을 제시했습니다.
이러한 발전은 변압기 기반 및 멀티태스크 학습 접근 방식 모두의 중요성이 커지고 있음을 보여줍니다.
특히 화재 감지와 같이 정확한 분류와 감지가 모두 중요한 특수 응용 분야에서 더욱 그렇습니다.
제안된 앙상블 모델은 두 가지 관점에서 중요한 차별화를 포함합니다. 첫 번째 관점은 화재와 연기뿐만 아니라 "안개" 및 "구름"과 같은 연기와 유사한 특징과 "빛" 및 "햇빛"과 같은 화재와 유사한 특징을 포함하는 데이터로 모델을 학습하여 연기, 안개, 구름, 불, 빛, 햇빛을 분류하는 것입니다. 둘째, 하나의 딥러닝 모델에만 의존하는 대신, ResNeXt-50 및 EfficientNet-B4와 같은 여러 분류 모델을 병렬로 구축하여 이미지를 동시에 분류하고 강력한 객체 탐지 모델인 Yolov5를 사용하여 상황 설명을 추출합니다. 이후, 분류된 이미지와 탐지된 객체를 앙상블 모델에 동시에 학습시켜 분류 및 탐지 효율을 극대화하고 전반적인 성능을 향상시킵니다.
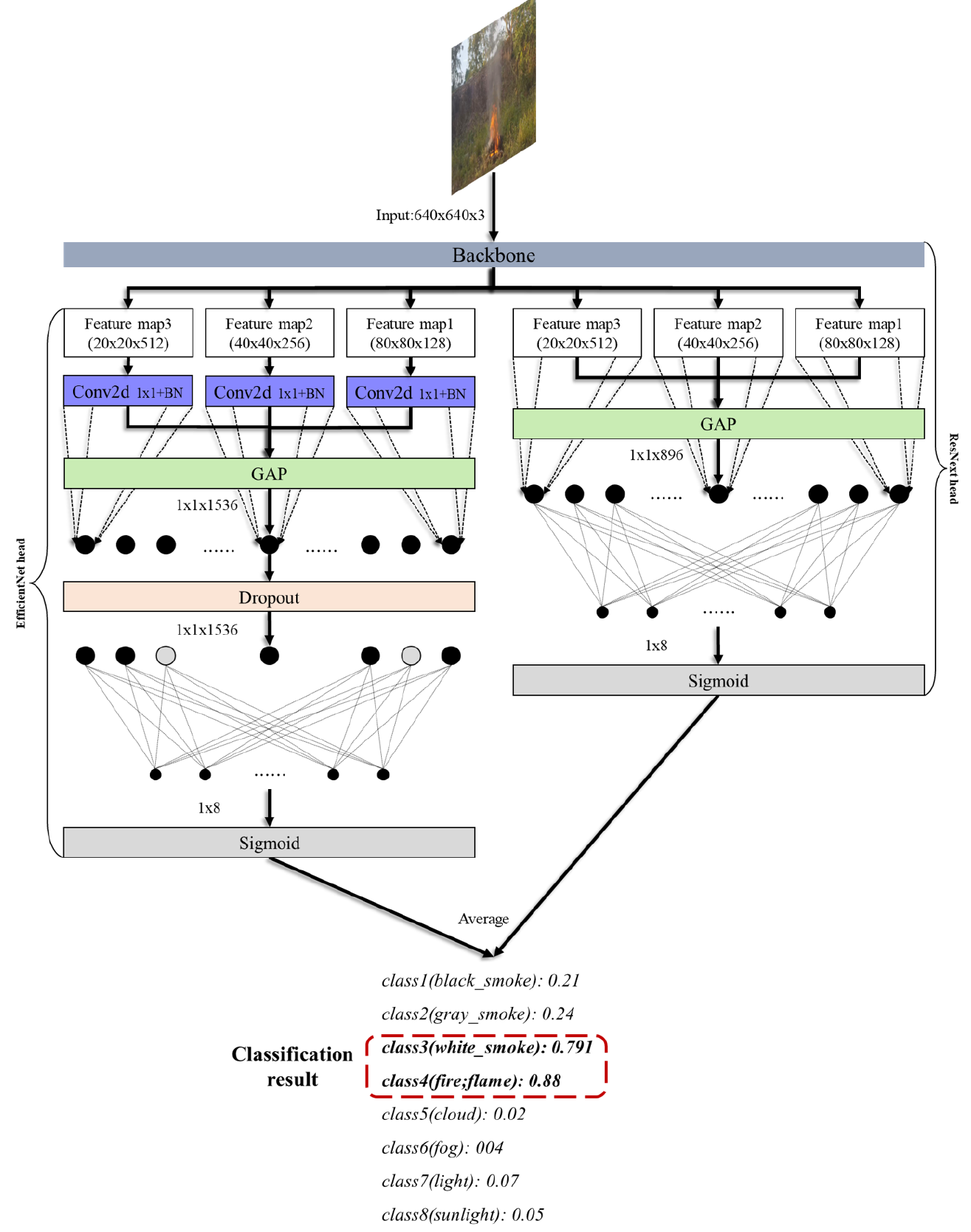
TABLE 2. Preprocessed dataset.


III. MATERIALS AND METHODS
III. 재료 및 방법
A. DATASET
A. 데이터셋
The experimental data used in this study were obtained from AI-Hub [20], which provides images of locations where fires
can occur, captured from videos of actual fire incidents. A total of 1.73 million fire images have been classified into
eleven categories. These videos were recorded by AI-Hub, where various materials such as wood, paper, rubber, oil,
branches, leaves, and waste paper were burned, with a camera fixed at candidate locations for potential
CCTV installation.
본 연구에 사용된 실험 데이터는 실제 화재 사고 영상을 통해 화재 발생 가능 위치의 이미지를 제공하는 AI-Hub[20]에서 얻었습니다. 총 173만 개의 화재 이미지가 11가지 범주로 분류되었습니다. 이 영상들은 AI-Hub에서 녹화되었으며, 목재, 종이, 고무, 기름, 나뭇가지, 나뭇잎, 폐지 등 다양한 재료를 태우는 모습을 담았습니다. CCTV 설치 후보 위치에 카메라를 고정하여 촬영했습니다.
The selected locations included 18 different environments: fields, mountains, forests, farms, and reservoirs. For each
scene -fire, similar, and non-fire - a total of 500 videos, each lasting 15 minutes, were acquired. To minimize redundancy,
filming was conducted only once at each location under different lighting conditions, including sunrise, daytime, and
sunset. From these videos, images were extracted at a rate of 3 to 5 frames per second to construct
a dataset for forest fire detection.
Following a thorough review of all 1.73 million images, images with incorrectly annotated bounding boxes or incorrect
class labels are removed and annotated again using Labelme. We construct eight classes with 8,000 images for each
class, comprising a total of 64,000 images. The annotation processing of the raw data set is conducted via drawing, and
the error rate is less than 1%. Table 1 shows that items (class label and bounding box) are added to each
image’s annotation file according to the existence of the class while capturing images in various places.
Therefore, multiple classes can exist in the annotation file of an image. Table 1 presents the details of the dataset.
First, it is primarily classified into three scenes, and then subclassified into eleven classes. In the fire
scene, fire (flame) and smoke of three colors are classified into various classes.
Similar scenes that cause false detections include clouds and fog, which are similar to smoke, as well as
light and sunlight, which resemble fire. Finally, an irrelevant scene includes the other corresponding images. Because our
problem focuses on detecting fire and smoke and discriminating between fog and clouds, which are comparable to
smoke, we exclude three classes from the training dataset: moving objects, trees&grass, and background. We attempt to
increase the number of images and improve accuracy using this method.
선택된 장소는 들판, 산, 숲, 농장, 저수지 등 18개의 서로 다른 환경을 포함했습니다.
각 장면(화재, 유사 장면, 비화재 장면)에 대해 각각 15분 분량의 총 500개의 영상을 수집했습니다.
중복을 최소화하기 위해 일출, 낮, 일몰 등 다양한 조명 조건에서 각 위치에서 한 번만 촬영했습니다.
이 영상들에서 초당 3~5프레임의 속도로 이미지를 추출하여 산불 감지 데이터 세트를 구축했습니다.
173만 개의 이미지를 모두 면밀히 검토한 후, 경계 상자에 잘못 주석이 지정되었거나 잘못된 클래스 레이블이 있는 이미지를 제거하고 Labelme을 사용하여 다시 주석을 달았습니다.
각 클래스당 8,000개의 이미지로 구성된 8개의 클래스를 구축하여 총 64,000개의 이미지를 구성했습니다. 원시 데이터 세트의 주석 처리는 드로잉을 통해 수행되었으며, 오류율은 1% 미만입니다.
표 1은 다양한 위치에서 이미지를 촬영하는 동안 각 이미지의 주석 파일에 항목(클래스 레이블 및 경계 상자)이 클래스 존재 여부에 따라 추가되는 방식을 보여줍니다.
따라서 이미지의 주석 파일에는 여러 클래스가 존재할 수 있습니다. 표 1은 데이터셋의 세부 정보를 보여줍니다.
먼저, 이미지는 세 가지 장면으로 분류되고, 그 후 11개의 클래스로 세분화됩니다.
화재 장면에서 세 가지 색상의 불(불꽃)과 연기는 다양한 클래스로 분류됩니다.
오탐지를 유발하는 유사 장면에는 연기와 유사한 구름과 안개, 그리고 불과 유사한 빛과 햇빛이 포함됩니다.
마지막으로, 무관한 장면에는 다른 해당 이미지들이 포함됩니다. 본 연구에서는 화재와 연기를 감지하고 연기와 유사한 안개와 구름을 구분하는 데 중점을 두므로, 학습 데이터셋에서 움직이는 물체, 나무와 풀, 배경의 세 가지 클래스를 제외합니다.
이 방법을 사용하여 이미지 수를 늘리고 정확도를 향상시키고자 합니다.

Finally, we construct a training dataset with eight classes: smoke with three colors, fire, clouds, fog, light, and sunlight.
Light and sunlight are included due to their similarity to fire, while fog and clouds are considered because of their
resemblance to smoke. A total of 64,000 images containing 91,337 objects are constructed as training, valid, and test
datasets in an 8:1:1 ratio. Multiple objects may exist in an image. Therefore, objects in Table 2 refer to the number of
objects in the entire image per class.
마지막으로, 세 가지 색상의 연기, 불, 구름, 안개, 빛, 햇빛 등 8개 클래스로 구성된 학습 데이터셋을 구축합니다. 빛과 햇빛은 불과 유사하기 때문에 포함되고, 안개와 구름은 연기와 유사하기 때문에 고려됩니다. 91,337개의 객체를 포함하는 총 64,000개의 이미지가 학습 데이터셋, 유효 데이터셋, 테스트 데이터셋으로 8:1:1 비율로 구축됩니다. 한 이미지에 여러 객체가 존재할 수 있습니다. 따라서 표 2의 객체는 전체 이미지에서 클래스당 객체의 수를 나타냅니다.
B. PROPOSED MODEL
The objective of this study is to minimize the damage caused by fire outbreaks using fast and accurate image classification and detection. Therefore, faster and more precise detection models are required.
In this paper, we propose FDN to improve the detection and classification performance.
By constructing two classification models in parallel, we develop a model that classifies the same image simultaneously and uses a powerful object detection model, Yolov5, to extract information about the situation depicted in the image.
This aids in determining the more accurate classification. Moreover, if the classification is well-trained, it can help improve
the performance of object detection.
B. 제안 모델
본 연구의 목적은 빠르고 정확한 이미지 분류 및 탐지를 통해 화재 발생으로 인한 피해를 최소화하는 것입니다. 따라서 더욱 빠르고 정확한 탐지 모델이 필요합니다.
본 논문에서는 탐지 및 분류 성능 향상을 위해 FDN(Full-Dynamic Network)을 제안합니다.
두 개의 분류 모델을 병렬로 구축하여 동일한 이미지를 동시에 분류하고, 강력한 객체 탐지 모델인 Yolov5를 사용하여 이미지에 나타난 상황에 대한 정보를 추출하는 모델을 개발합니다.
이는 더욱 정확한 분류를 결정하는 데 도움이 됩니다. 또한, 분류가 잘 학습되면 객체 탐지 성능 향상에 도움이 될 수 있습니다.
1) Model Framework
As shown in Figure 1, there are three outputs from FDN.
The first and second methods use the average of the image classification predictions to compute the correct classes.
Instead of having only one label, multiple labels can be used to obtain results for any number of cases. The last method
uses object detection results simultaneously to predict the detection and location of fires, smoke, and other relevant
objects. In this framework, we expect that a fire or smoke that is not detected will be classified through the classification
phase, or the fire or smoke that is not classified will be detected through the detection phase. This reduces the miss
rate and number of false alarms; thus, they can complement each other’s performance. The state-of-the-art model Yolov5
is used for detection, and ResNeXt-50 and EfficientNet-B4 are used for classification.
1) 모델 프레임워크
그림 1에서 볼 수 있듯이 FDN에는 세 가지 출력이 있습니다.
첫 번째와 두 번째 방법은 이미지 분류 예측의 평균을 사용하여 정확한 클래스를 계산합니다.
레이블을 하나만 사용하는 대신 여러 레이블을 사용하여 여러 사례에 대한 결과를 얻을 수 있습니다. 마지막 방법은
객체 감지 결과를 동시에 사용하여 화재, 연기 및 기타 관련 객체의 감지 및 위치를 예측합니다.
이 프레임워크에서는 감지되지 않은 화재 또는 연기가 분류 단계를 통해 분류되거나,
분류되지 않은 화재 또는 연기가 감지 단계를 통해 감지될 것으로 예상합니다. 이를 통해 오탐률과 오경보 수가 감소하여 서로의 성능을 보완할 수 있습니다. 감지에는 최첨단 모델인 Yolov5가 사용되고, 분류에는 ResNeXt-50과 EfficientNet-B4가 사용됩니다.
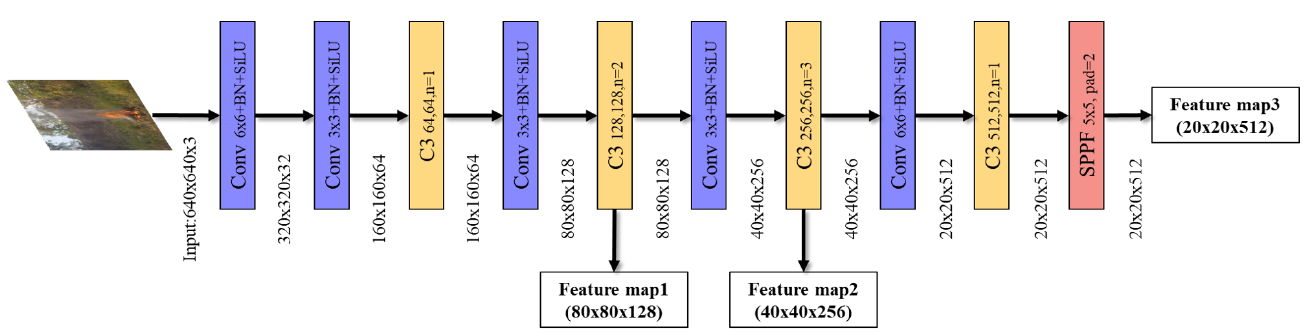
2) Backbone
The backbone is CSPDarknNet-53 [51], which is also the backbone of Yolov5 and is faster than the other backbones.
In FDN, we extract three different-sized feature maps using an FPN [45] and a path aggregation network (PAN) [62]. As
shown in Figure 2, the structure of the backbone comprises a backbone connection based on cross stage partial
connections (CSP) [63] and spatial pyramid pooling (SPP) [41], as well as conv, C3, and spatial pyramid pooling-fast (SPPF) blocks. The Conv block integrates general convolution operations with batch normalization
and sigmoid linear unit(SiLU) activation function. The detailed internal structure of C3 block is shown in Figure 3,
which uses BottleneckCSP to evenly distribute the computation of each layer to eliminate
the computation bottleneck and upgrade the computation utilization of the CNN layer [63]. SPPF block utilizes the SPP
concept to improve performance by pooling feature maps into filters of various sizes and then combining them. A detailed
illustration of the SPPF block is shown in Figure 3.
2) 백본
백본은 Yolov5의 백본이기도 한 CSPDarknNet-53[51]이며, 다른 백본보다 빠릅니다.
FDN에서는 FPN[45]과 경로 집계 네트워크(PAN)[62]를 사용하여 세 가지 크기의 특징 맵을 추출합니다.
그림 2에서 볼 수 있듯이, 백본의 구조는 교차 단계 부분 연결(CSP)[63]과 공간 피라미드 풀링(SPP)[41]을 기반으로 하는 백본 연결과 conv, C3, 공간 피라미드 풀링-고속(SPPF) 블록으로 구성됩니다. Conv 블록은 일반적인 합성곱 연산과 배치 정규화 및 시그모이드 선형 단위(SiLU) 활성화 함수를 통합합니다. C3 블록의 자세한 내부 구조는 그림 3에 나와 있으며,
BottleneckCSP를 사용하여 각 계층의 계산을 균등하게 분배하여 계산 병목 현상을 제거하고 CNN 계층의 계산 활용도를 향상시킵니다[63]. SPPF 블록은 SPP 개념을 활용하여 특징 맵을 다양한 크기의 필터로 풀링한 후 이를 결합하여 성능을 향상시킵니다. SPPF 블록의 자세한 그림은 그림 3에 나와 있습니다.
3) Head
The head of the FDN is classified, and the detected output is derived. As described in the model framework, there are
two phases: classification and detection. In the classification phase, as shown in Figure 4, each feature map
passes through Global Average Pooling (GAP). The sigmoid function is then utilized through the fully connected
layer to obtain the result. Because there are two outputs, we use late average fusion to maintain the average value
as the final result of the classification phase and set a threshold for multiple classes to determine only those
classes higher than a specific value as the final class. The threshold is defined as the arithmetic mean
of the maximum and minimum values of the final sigmoid output. In the detection phase, as shown in Figure 5, we
utilize FPN [45] and PAN [62] to obtain results using all three different feature maps. The result is a vector containing
13 pieces of information, where each value represents the following: conditional probabilities for each class, center_x
and center_y coordinates of the bounding box, width and height of the bounding box, and the confidence score of the
bounding box.
3) 헤드
FDN의 헤드를 분류하고 검출된 출력을 도출합니다. 모델 프레임워크에 설명된 바와 같이, 분류와 검출의 두 단계가 있습니다. 그림 4와 같이 분류 단계에서는 각 특징 맵이 전역 평균 풀링(GAP)을 거칩니다. 그런 다음 시그모이드 함수를 완전 연결 계층을 통해 활용하여 결과를 얻습니다. 두 개의 출력이 있으므로, 후기 평균 융합(late average fusion)을 사용하여 평균값을 분류 단계의 최종 결과로 유지하고, 여러 클래스에 대한 임계값을 설정하여 특정 값보다 높은 클래스만 최종 클래스로 결정합니다. 임계값은 최종 시그모이드 출력의 최대값과 최소값의 산술 평균으로 정의됩니다. 그림 5와 같이 검출 단계에서는 FPN[45]과 PAN[62]을 활용하여 세 가지 특징 맵을 모두 사용하여 결과를 얻습니다. 결과는 13개의 정보를 포함하는 벡터이며, 각 값은 각 클래스에 대한 조건부 확률, 경계 상자의 center_x 및 center_y 좌표, 경계 상자의 너비와 높이, 그리고 경계 상자의 신뢰도 점수를 나타냅니다.



IV. RESULTS
TABLE 3. Comparison in the classification phase.

1) Loss function
As the FDN outputs three different values (two from classification
and one from detection), three loss values are
calculated. The binary cross-entropy (BCE) loss is used in
the classification phase for multilabel classification. In the
detection phase, the complete intersection over union (CIoU)
loss is applied for the bounding box coordinate regression
Lreg and BCELogitloss for both classes Lcls and the object
Lobj . BCEwithLogitsLoss is a sigmoid layer added to BCE,
which is a loss function used in case more than two classes.
In the classification phase, BCELoss is preferred over BCELogitLoss
owing to the presence of a sigmoid layer in the head.
The FDN loss function LFDN consists of the above three errors, and it is defined as follows:

where α1, α2, and β denote the loss weighting parameters
for each task (Algorithm 1), and the operations of three errors
are as follows:

where Bbox, cls, and conf denote the predicted bounding
box coordinates, classification probability, confidence score,
and ground truth, respectively. BboxGT , clsGT , and confGT
denote the corresponding ground truth, respectively.
The details of loss weighting are shown in Algorithm 1.
An essential part of loss weighting is the calculation and
backpropagation of each task’s loss value. We propose partial
loss-balanced task weighting (P-LBTW), which partially
applies loss-balanced task weighting (LBTW) from [64] only
to classification losses and assigns different weights to the
final classification and detection losses. Instead of using the
loss values obtained by LBTW as an average, we obtain the
optimal weight values of 0.5 and 0.6 through experiments.
Therefore, 0.5 for FDN(0.5) and 0.6 for FDN(0.6) are listed
in Tables 3, 4, 6, and 7 and are the weights of the loss values
of each detection phase. The remaining weighted values are
distributed into Classifications 1 and 2 in equal proportion.
TABLE 5. Table showing the settings of DETR, DETR-tiny, and DETR-small.

In this section, we discuss the experimental environment,
hyperparameter settings, evaluation metrics, performance
metric analysis by class per phase, and ablation
studies. The performances of two classification models
(ResNeXt-50(32x4d), EfficientNet-B4) and three object detection
model (Yolov5s, DETR-tiny, DETR-small) for classifying
and detecting refined fire-related data are individually
tested and compared to FDN. To demonstrate the superior
performance of FDN, a comparative analysis is conducted
with DETR, a representative transformer-based object detection
model. However, in this study, YOLOv5s is used instead
of YOLOv5l or YOLOv5x for application in limited environments,
as it enables efficient and fast detection with fewer parameters and lower computational cost. To further optimize
the DETR, the high number of parameters and FLOPs of
DETR are reduced to enhance efficiency. In DETR-tiny and
DETR-small, ResNet18 is used as the backbone instead of
ResNet50, and the number of encoding and decoding layers
is reduced to 1/3 and 1/2, respectively, to enable an accurate
comparison with YOLOv5s and FDN. The details of the
lightweight optimization are presented in Table 5. As shown
in Tables 3 and 6, the proposed ensemble model, FDN,
outperforms the individual models for all metrics.
A. EXPERIMENTAL SETUP AND HYPER-PARAMETER
We conduct the experiments on a computer with an AMD
Threadripper PRO 3955WX 16-Core Processor (3.90 GHz)
with 256 GB of main memory. Two NVIDIA GeForce RTX
A6000 GPUs with 48 GB of memory are used for training
and inference. We utilize the PyTorch deep-learning framework
on a Windows 11 platform to develop and train the
FDN. The detection phase in FDN utilizes portions of code
from Yolov5s [21]. The proposed model is trained for 100
epochs using the default input size of 640 × 640 pixels. The
batch size is set to 128, and a stochastic gradient descent
(SGD) optimizer is used with a momentum of 0.937, learning
rate of 0.01, and weight decay of 0.0005. The confidence and
IoU thresholds is set to 0.001 and 0.60, respectively. The
hyperparameters are chosen based on empirical experimentation,
prior classification, and object detection research.
To prevent overfitting, a dataloader is generated with
vertical and horizontal flips set to percent=0.5 during the
image preprocessing step. In the model design, batch normalization
is applied to all convolutional blocks, ensuring
stable training. Additionally, during the learning process,
MultiplicativeLR, one of PyTorch’s learning rate schedulers,
is employed to adjust the learning rate at every epoch. These
strategies collectively contribute to reducing overfitting and
improving generalization.
B. EVALUATION METRICS
We use a confusion matrix for both phases to derive the accuracy,
precision, recall, and F1-score for the entire dataset and
each class. Figure 9 provides a visual representation of this
process, illustrating how the confusion matrix is constructed
and utilized in our evaluation. In the detection phase, we
use the mAP to compare the performance of each class with
mAP@50 and mAP@50:95 as additional evaluation metrics.
In mAP@50, @ followed by 50 indicates the IoU threshold,
and 50:95 implies the average of the mAP measured by
increasing the IoU threshold in Step 5. The equations for
calculating the mentioned evaluation metrics are as follows:
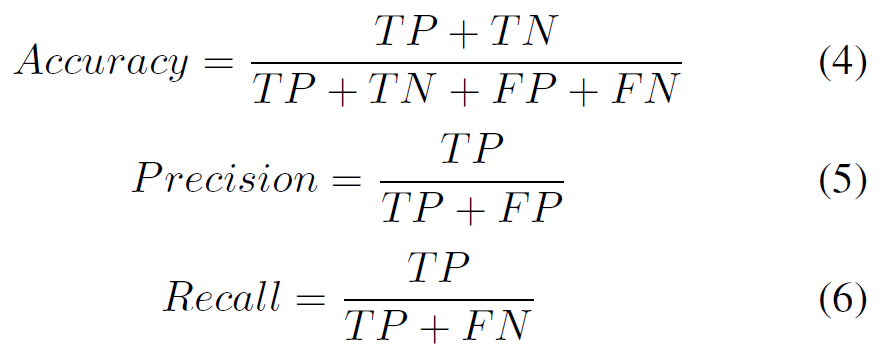
TABLE 4. Result of classification phase in FDN.


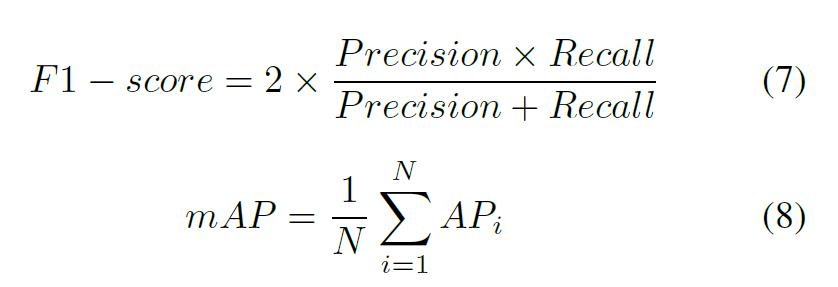
TABLE 6. Comparison in the detection phase.
C. CLASSIFICATION PHASE
The results of the classification phase study are divided
into F1-score, recall, precision, and accuracy to compare FDN with the two classification models (ResNeXt-50 and
EfficientNet-B4). Compared to the other two models, FDN
achieves a higher F1-score in all classification categories,
exhibiting performance improvements of 11.3% and 13.5%
over ResNeXt-50 and EfficientNet-B4, respectively. In particular,
it outperforms both models by up to 30% for black,
gray, and white smoke, which are the first classes found in
a fire. This is a significant improvement, considering that
smoke from a fire must be classified quickly. In terms of
recall, FDN achieves 12.3% and 12.9% higher recall than
ResNeXt-50 and EfficientNet-B4, respectively. Further, FDN
achieves 10.2% and 13.9% higher precision for ResNeXt-
50 and EfficientNet-B4, respectively. Finally, FDN has the
highest accuracy compared to the other two models, indicating
that FDN could predict all instances more accurately on
average. The details are presented in Table 4.

D. DETECTION PHASE
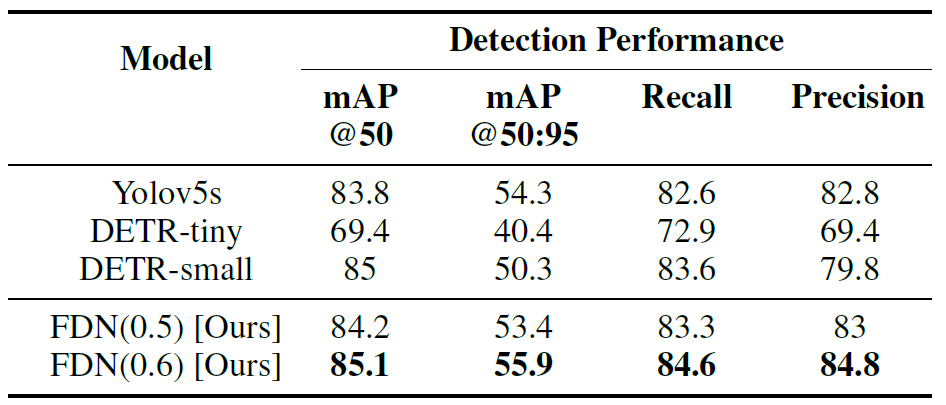
The results of the detection phase differ slightly from
the evaluation of classification when comparing FDN with
YOLOv5s, DETR-tiny, and DETR-small using mAP@50
and mAP@50:95 with IoU threshold, recall, and precision.
mAP implies the average precision when the detected
bounding box below a specified IoU threshold is removed.
Therefore, with the increase in IoU threshold, more bounding boxes are removed, which can result in differences in
performance metrics. As shown in Table 7, FDN, which is
the same one-stage detector model as Yolov5s, outperforms
Yolov5s on mAP@50 and mAP@50:95 by up to 1.3% and
1.6% respectively, and performs well in all classes. This
shows that FDN provides a more accurate object location
and presence than Yolov5s. FDN outperforms Yolov5s by
1.8% and 2.0% in terms of recall and precision, respectively.
Furthermore, compared to DETR-tiny and DETR-small,
FDN demonstrates significant performance improvements.
Specifically, FDN achieves a 15.7% and 0.1% increase in
mAP@50 over DETR-tiny and DETR-small, respectively,
while also improving mAP@50:95 by 15.5% and 5.6%,
respectively. In terms of recall, FDN outperforms DETR-tiny
and DETR-small by 11.7% and 1.0%, respectively. Similarly,
FDN shows a 15.4% and 5.0% improvement in precision
over DETR-tiny and DETR-small, respectively. These results
highlight FDN’s effectiveness in both detection accuracy
and localization compared to not only YOLOv5s but also
transformer-based models like DETR-tiny and DETR-small
E. MODEL COMPARISON
Another advantage of FDN is that it requires less computation
owing to the small number of parameters and relatively
small FLOPs. However, because classification and detection are performed simultaneously, it may require more computation
and parameters than ResNeXt-50 and EfficientNet-B4,
respectively. Nevertheless, as shown in Table 8, the number
of parameters is reduced by 33.6% and 44.2%, respectively,
and the performance improves. Compared to the detection
model YOLOv5s, the computation in terms of floating point
operations (FLOPs) is reduced by 58.3%, as shown in Table
8. Similarly, compared to DETR-tiny and DETR-small,
FLOPs are reduced by 56.5% and 58.3%, respectively. While
FDN maintains a similar FPS and number of parameters to
YOLOv5s, it significantly reduces the number of parameters
by 27% and 37.8% compared to DETR-tiny and DETR-small respectively. This reduction is crucial, as detection
models are often deployed in environments with limited
computational resources where fires occur.
In [65], Yolov5s with a batch size of 32 is used to
demonstrate the feasibility of real-time forest fire detection
in resource-constrained environments using real cameras. As
shown in Table 8, there is almost no parameter difference
between FDN and Yolov5s. However, with FLOPs reduced
to 58.3% of Yolov5s, FDN requires significantly less computation,
making it a suitable choice for deployment in environments
with limited resources. Furthermore, since the batch
size was set to 128 during training and FLOPs calculation, memory utilization can be further optimized by reducing the
batch size during testing. These results indicate that FDN
offers an efficient and practical solution for real-time fire
detection.
TABLE 7. Result of detection phase in FDN.

TABLE 8. Table showing the input size, FPS, FLOPs, and parameters of FDN and comparison models.


TABLE 9. Comparison of loss weighting methods.

F. ABLATION STUDY
Because more than three loss values are backpropagated in
the FDN model, we conduct an ablation study regarding loss
weighting. LBTW, which is suitable for general multitask
learning, is compared with P-LBTW, which partially applies
LBTW and reweighting. To optimize the balanced classification
performance and detection of FDN using P-LBTW, we
adjust the ratio of the values for each loss. To ensure that each
parameter has a value of at least 0.1 and a ratio higher than
the average weighted loss (LBTW) of 0.33, the ratio of the
detection loss is analyzed via grid search within 0.4–0.8 in
steps of 0.1.
1) Average with LBTW
2) Weighting with P-LBTW
• β = 0.4 : 0.8 in Equation (1)
In Figure 10, the LBTW graph train with the mean value
shows that the classification loss values do not converge in
either the training or valid phases. However, P-LBTW (0.6)
shows that the classification losses for the training and valid
phases are considerably lower than LBTW and converge
stably. In addition, the detection loss appears to converge
for both methods; however, both (b) and (d) in Figure 10
show that P-LBTW converges to a lower value than LBTW.
The performance comparison also indicates that P-LBTW is
superior to LBTW. As shown in Table 9, there is only a slight
improvement in the classification performance; however, the
detection performance exhibits a significant improvement in
mAP@50 and mAP@50:95, with 4.5% and 8.6%, respectively.
Therefore, we prove that P-LBTW is more suitable
than LBTW for the data used in this study.
In addition, we compare the loss weights of 0.7 and
0.8, which are higher than 0.6. As shown in Figure 11, PLBTW(
0.7) and P-LBTW(0.8) exhibit convergence and stability
for losses that are not significantly different from those
of P-LBTW(0.6). However, when we test the performance,
the overall performance of classification and detection is
observed to decrease, as shown in Table 9. Therefore, it
proves that loss weighting above P-LBTW(0.6) degrades the
performance of FDN.
V. DISCUSSION
The proposed method contributes to the initial fire suppression
by providing a service and system configuration
applicable in the field. The F1-score of a single classification
model remains at approximately 86% when multiple objects
are detected in a single image. However, the performance
of the F1-score improves to a maximum of 34.4% by the
classification and detection ensemble model, which is the
FDN. In addition, the FDN improves the mAP by up to 4.3%
for certain classes compared to the single detection model and improves the mAP value for all classes by more than
1.3%. These results will enable early-stage fire suppression
through rapid detection of large and small fires in forests or
wilds that are vulnerable to fire.
Furthermore, the proposed FDN model demonstrates
strong scalability and real-world adaptability, making it applicable
to fire-prone environments such as forests, urban
areas, and industrial sites. By integrating larger datasets and
considering environmental factors like lighting, weather, and
atmospheric conditions such as fog, clouds, and varying
smoke colors, FDN ensures robust detection capabilities.
Its compatibility with real-world fire monitoring systems,
including drones, CCTV, and satellite imagery, enables seamless
deployment across different locations. Additionally, the
framework has the potential to be adapted for various fire
detection applications, including industrial and residential
settings, as well as post-disaster fire risk assessment. By
incorporating region-specific fire characteristics as domain
knowledge, FDN allows for customizable detection systems,
making it a valuable tool for proactive fire management and
mitigation strategies.
VI. CONCLUSION
This study proposes an ensemble model that classifies and
detects different colors of smoke, fog, clouds, fire, light, and
sunlight. Performance improvement is expected through a
classification and detection ensemble model, and an investigation
of the ensemble model shows that the F1-score in
the classification phase and mAP in the detection phase are
improved by up to 34.4% and 4.3%, respectively, compared
to the individual model. With an increased number of fire
accidents, more accurate fire reports are required, and it may
be possible to reduce them. Fire accidents will decrease if a
model distinguishes fire, light, or sunlight by examining little
light or by checking the possibility of white smoke, clouds, or
fog by examining simple smoke. Accordingly, the proposed
economic real-time fire detection system advances initial
fire suppression by providing service and system configurations
applicable in the field, thus minimizing the damage
caused by fire. A methodology for predicting fires using 3D
CNN, rather than simple fire detection, could be additionally
studied. Using time information to recognize time-series
data, the system can predict the occurrence of a fire using
a regression model through time-aware Transformers. The
extent of damage varies significantly depending on whether
a fire is initially extinguished. We believe that CCTV using
our method can detect fires in real-time and enable initial
suppression, contributing to society by protecting the natural
environment and ecosystems.
DATA AVAILABILITY
This research uses datasets from ‘The Open AI Dataset
Project (AI-Hub, S. Korea)’. All data information can be
accessed through ‘AI-Hub (http://www.aihub.or.kr)’.
Lisboa, and A. V. Barbosa, “An automatic
fire detection system based on deep convolutional neural networks
for low-power, resource-constrained devices,” Neural Computing and
Applications, vol. 34, pp. 15 349–15 368, 06 2022. [Online]. Available:
https://github.com/gaiasd/DFireDataset
[6] F. Safarov, S. Muksimova, M. Kamoliddin, and Y. I. Cho, “Fire and smoke
detection in complex environments,” Fire, vol. 7, pp. 389–389, 10 2024.
[7] M. N. Mowla, D. Asadi, S. Masum, and K. Rabie, “Adaptive hierarchical
multi-headed convolutional neural network with modified convolutional
block attention for aerial forest fire detection,” IEEE Access, pp. 1–1, 01
2024. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/
10818623
[8] B. Senthilnayaki, M. A. Devi, S. A. Roseline, and P. Dharanyadevi,
“Deep learning-based fire and smoke detection system,” pp. 1–6, 02
2024. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/
10493463/
[9] P. Li and W. Zhao, “Image fire detection algorithms based on convolutional
neural networks,” Case Studies in Thermal Engineering, vol. 19, p.
100625, 06 2020.
[10] R. S. Priya and K. Vani, “Deep learning based forest fire classification and
detection in satellite images,” IEEE Xplore, p. 61–65, 12 2019.
[11] Q.-x. Zhang, G.-h. Lin, Y.-m. Zhang, G. Xu, and J.-j. Wang, “Wildland
forest fire smoke detection based on faster r-cnn using synthetic smoke
images,” Procedia Engineering, vol. 211, pp. 441–446, 2018.
[12] Y. Xie and M. Peng, “Forest fire forecasting using ensemble learning
approaches,” Neural Computing and Applications, vol. 31, 05 2018.
[13] N. Qu, Z. Li, X. Li, S. Zhang, and T. Zheng, “Multi-parameter fire
detection method based on feature depth extraction and stacking ensemble
learning model,” Fire Safety Journal, vol. 128, p. 103541, 03 2022.
[14] H. C. Reis and V. Turk, “Detection of forest fire using deep
convolutional neural networks with transfer learning approach,” Applied
Soft Computing, vol. 143, p. 110362, 08 2023. [Online]. Available: https:
//http://www.sciencedirect.com/science/article/abs/pii/S1568494623003800
[15] R. Xu, H. Lin, K. Lu, L. Cao, and Y. Liu, “A forest fire detection system
based on ensemble learning,” Forests, vol. 12, p. 217, 02 2021.
[16] R. Ghali and M. A. Akhloufi, “Deep learning approaches for wildland
fires remote sensing: Classification, detection, and segmentation,” Remote
Sensing, vol. 15, p. 1821, 03 2023.
[17] R. Ghali, M. A. Akhloufi, and W. S. Mseddi, “Deep learning and transformer
approaches for uav-based wildfire detection and segmentation,”
Sensors, vol. 22, p. 1977, 03 2022.
[18] H. Yar, Z. A. Khan, M. Ullah, W. Ullah, and S. W. Baik, “A modified
yolov5 architecture for efficient fire detection in smart cities,” Expert
Systems with Applications, vol. 231, pp. 120 465–120 465, 11 2023.
[19] S. Dogan, P. Datta Barua, H. Kutlu, M. Baygin, H. Fujita, T. Tuncer, and
U. Acharya, “Automated accurate fire detection system using ensemble
pretrained residual network,” Expert Systems with Applications, vol. 203,
p. 117407, 10 2022.
[20] AI-Hub, “Fire prediction video, ai-hub dataset,” AI-Hub, 2021. [Online].
Available: https://www.aihub.or.kr
[21] G. Jocher, “ultralytics/yolov5,” https://github.com/ultralytics/yolov5,
GitHub, 2020. [Online]. Available: https://github.com/ultralytics/yolov5
[22] A. Gaur, A. Singh, A. Kumar, K. S. Kulkarni, S. Lala, K. Kapoor, V. Srivastava,
A. Kumar, and S. C. Mukhopadhyay, “Fire sensing technologies:
A review,” IEEE Sensors Journal, vol. 19, pp. 3191–3202, 05 2019.
[23] D. Gutmacher, U. Hoefer, and J. Wöllenstein, “Gas sensor technologies for
fire detection,” Sensors and Actuators B: Chemical, vol. 175, pp. 40–45,
12 2012.
[24] T. Celik, “Fast and efficient method for fire detection using image processing,”
ETRI Journal, vol. 32, pp. 881–890, 12 2010.
[25] F. Vandecasteele, B. Merci, and S. Verstockt, “Smoke behaviour analysis
with multi-view smoke spread data.” Conference proceedings fourteenth
international Interflam conference, 2016.
[26] K. Poobalan and S.-C. Liew, “Fire detection based on color filters and bagof-
features classification,” 2015 IEEE Student Conference on Research
and Development (SCOReD). IEEE, 2015, pp. 389–392.
[27] N. I. binti Zaidi, N. A. A. binti Lokman, M. R. bin Daud, H. Achmad, and
K. A. Chia, “Fire recognition using rgb and ycbcr color space,” ARPN
Journal of Engineering and Applied Sciences, vol. 10, pp. 9786–9790,
2015.
[28] Y. Chunyu, F. Jun, W. Jinjun, and Z. Yongming, “Video fire smoke
detection using motion and color features,” Fire Technology, vol. 46, pp.
651–663, 10 2009.
[29] J. Gubbi, S. Marusic, and M. Palaniswami, “Smoke detection in video
using wavelets and support vector machines,” Fire Safety Journal, vol. 44,
pp. 1110–1115, 11 2009.
[30] S. Calderara, P. Piccinini, and R. Cucchiara, “Vision based smoke detection
system using image energy and color information,” Machine Vision
and Applications, vol. 22, pp. 705–719, 05 2010.
[31] W. Ye, J. Zhao, S. Wang, Y. Wang, D. Zhang, and Z. Yuan, “Dynamic
texture based smoke detection using surfacelet transform and hmt model,”
Fire Safety Journal, vol. 73, pp. 91–101, 04 2015.
[32] T. X. Tung and J.-M. Kim, “An effective four-stage smoke-detection
algorithm using video images for early fire-alarm systems,” Fire Safety
Journal, vol. 46, pp. 276–282, 07 2011.
[33] T. Celik, H. Demirel, H. Ozkaramanli, and M. Uyguroglu, “Fire detection
using statistical color model in video sequences,” Journal of Visual Communication
and Image Representation, vol. 18, pp. 176–185, 04 2007.
[34] G. F. Shidik, F. N. Adnan, C. Supriyanto, R. A. Pramunendar, and P. N.
Andono, “Multi color feature, background subtraction and time frame
selection for fire detection,” IEEE Xplore, p. 115–120, 11 2013.
[35] B. Lee and D. Han, “Real-time fire detection using camera sequence image
in tunnel environment,” Springer eBooks, pp. 1209–1220, 07 2007.
[36] M. Mueller, P. Karasev, I. Kolesov, and A. Tannenbaum, “Optical flow
estimation for flame detection in videos.” IEEE transactions on image
processing, vol. 22, pp. 2786–2797, 04 2013.
[37] H. Harkat, J. M. P. Nascimento, A. Bernardino, and H. F. T.
Ahmed, “Fire images classification based on a handcraft approach,”
Expert Systems with Applications, vol. 212, p. 118594, 02 2023.
[Online]. Available: https://www.sciencedirect.com/science/article/abs/
pii/S0957417422016499?via%3Dihub
[38] M. Hashemzadeh, N. Farajzadeh, and M. Heydari, “Smoke detection in
video using convolutional neural networks and efficient spatio-temporal
features,” Applied Soft Computing, vol. 128, p. 109496, 10 2022.
[39] H. Yar, Z. A. Khan, I. Rida, W. Ullah, M. J. Kim, and S. W. Baik, “An
efficient deep learning architecture for effective fire detection in smart
surveillance,” Image and vision computing, vol. 145, pp. 104 989–104 989,
05 2024.
[40] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich
feature hierarchies for accurate object detection and semantic
segmentation.” Proceedings of the IEEE Conference on Computer
Vision and Pattern Recognition (CVPR), 2014, pp. 580–587.
[Online]. Available: https://openaccess.thecvf.com/content_cvpr_2014/
html/Girshick_Rich_Feature_Hierarchies_2014_CVPR_paper
[41] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial pyramid pooling in deep
convolutional networks for visual recognition,” IEEE Transactions on
Pattern Analysis and Machine Intelligence, vol. 37, pp. 1904–1916, 09
2015.
[42] K. He, G. Gkioxari, P. Dollar, and R. Girshick, “Mask r-cnn.” Proceedings
of the IEEE International Conference on Computer Vision (ICCV),
2017, pp. 2961–2969. [Online]. Available: https://openaccess.thecvf.com/
content_iccv_2017/html/He_Mask_R-CNN_ICCV_2017_paper
[43] R. Girshick, “Fast r-cnn.” Proceedings of the IEEE International
Conference on Computer Vision (ICCV), 2015, pp. 1440–1448.
[Online]. Available: https://openaccess.thecvf.com/content_iccv_2015/
html/Girshick_Fast_R-CNN_ICCV_2015_paper
[44] R. Shaoqing, H. Kaiming, G. Ross, and S. Jian, “Faster r-cnn:
Towards real-time object detection with region proposal networks,”
vol. 28. Advances in Neural Information Processing Systems 28 (NIPS
2015), 2015. [Online]. Available: https://proceedings.neurips.cc/paper_
files/paper/2015/file/14bfa6bb14875e45bba028a21ed38046-Paper.pdf
[45] T.-Y. Lin, P. Dollar, R. Girshick, K. He, B. Hariharan, and
S. Belongie, “Feature pyramid networks for object detection.”
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 2117–2125. [Online].
Available: https://openaccess.thecvf.com/content_cvpr_2017/html/Lin_
Feature_Pyramid_Networks_CVPR_2017_paper
[46] Z. Cai and N. Vasconcelos, “Cascade r-cnn: Delving into high
quality object detection.” Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR), 2018, pp. 6154–
6162. [Online]. Available: https://openaccess.thecvf.com/content_cvpr_
2018/html/Cai_Cascade_R-CNN_Delving_CVPR_2018_paper
[47] X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable
detr: Deformable transformers for end-to-end object detection,” 03 2021.
[Online]. Available: https://arxiv.org/abs/2010.04159
[48] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C.
Berg, “Ssd: Single shot multibox detector,” vol. 9905, 2016, pp. 21–37.
[49] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once:
Unified, real-time object detection.” Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 779–788.
[Online]. Available: https://www.cv-foundation.org/openaccess/content_
cvpr_2016/html/Redmon_You_Only_Look_CVPR_2016_paper.html
[50] J. Redmon and A. Farhadi, “Yolo9000: better, faster, stronger.”
Proceedings of the IEEE Conference on Computer Vision
and Pattern Recognition (CVPR), 2017, pp. 7263–7271. [Online].
Available: https://openaccess.thecvf.com/content_cvpr_2017/html/
Redmon_YOLO9000_Better_Faster_CVPR_2017_paper
[51] A. Bochkovskiy, C.-Y. Wang, and H.-Y. M. Liao, “Yolov4: Optimal
speed and accuracy of object detection,” 04 2020. [Online]. Available:
https://arxiv.org/abs/2004.10934
[52] J. Redmon and A. Farhadi, “Yolov3: An incremental improvement,” 04
2018. [Online]. Available: https://arxiv.org/abs/1804.02767v1
[53] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollar, “Focal loss
for dense object detection.” Proceedings of the IEEE International
Conference on Computer Vision (ICCV), 2017, pp. 2980–2988.
[Online]. Available: https://openaccess.thecvf.com/content_iccv_2017/
html/Lin_Focal_Loss_for_ICCV_2017_paper
[54] K. Duan, S. Bai, L. Xie, H. Qi, Q. Huang, and
Q. Tian, “Centernet: Keypoint triplets for object detection.”
Proceedings of the IEEE/CVF International Conference on
Computer Vision (ICCV), 2019, pp. 6569–6578. [Online]. Available:
https://openaccess.thecvf.com/content_ICCV_2019/html/Duan_
CenterNet_Keypoint_Triplets_for_Object_Detection_ICCV_2019_paper
[55] M. Tan, R. Pang, and Q. V. Le, “Efficientdet: Scalable and
efficient object detection.” Proceedings of the IEEE/CVF
Conference on Computer Vision and Pattern Recognition
(CVPR), 2020, pp. 10 781–10 790. [Online]. Available: https:
//openaccess.thecvf.com/content_CVPR_2020/html/Tan_EfficientDet_
Scalable_and_Efficient_Object_Detection_CVPR_2020_paper
[56] F. Guede-Fernández, L. Martins, R. V. de Almeida, H. Gamboa, and
P. Vieira, “A deep learning based object identification system for forest
fire detection,” Fire, vol. 4, p. 75, 10 2021.
[57] C. Zhang, Y. Zhang, L. Zhu, D. Liu, L. Wu, B. Li, S. Zhang,
M. Bennamoun, and F. Boussaid, “Uiformer: A unified transformerbased
framework for incremental few-shot object detection and instance
segmentation,” arXiv.org, 2024. [Online]. Available: https://arxiv.org/abs/
2411.08569
[58] I. Díaz, P. Loncomilla, and J. Ruiz-Del-Solar, “Yotor-you
only transform one representation,” pp. 1–6, 11 2024.
[Online]. Available: https://ieeexplore.ieee.org/abstract/document/
10814874?casa_token=qNdVXtGqVg0AAAAA:lJS2kmwEXQrzbtJPk2_
iumeBPxzFpN31xQbHUQgQesSeJiyZMHnSwtU6T4cGK7-tKDI1gPO7KQ
[59] Y. Peng, H. Li, Y. Zhang, X. Sun, and F.Wu, “Scene adaptive sparse transformer
for event-based object detection,” in Proceedings of the IEEE/CVF
Conference on Computer Vision and Pattern Recognition (CVPR), June
2024, pp. 16 794–16 804.
[60] Y. Ren, Y. Li, and A. W.-K. Kong, “Adaptive multi-task learning for fewshot
object detection,” in Computer Vision – ECCV 2024. Cham:
Springer Nature Switzerland, 2025, pp. 297–314.
[61] I. Tolstykh, M. Chernyshov, and M. Kuprashevich, “Cerberusdet: Unified
multi-dataset object detection,” arXiv.org, 2024. [Online]. Available:
https://arxiv.org/abs/2407.12632
[62] S. Liu, L. Qi, H. Qin, J. Shi, and J. Jia, “Path aggregation
network for instance segmentation.” 2018, pp. 8759–8768. [Online].
Available: https://openaccess.thecvf.com/content_cvpr_2018/html/Liu_
Path_Aggregation_Network_CVPR_2018_paper
[63] C.-Y. Wang, H.-Y. M. Liao, Y.-H. Wu, P.-Y. Chen, J.-W. Hsieh,
and I.-H. Yeh, “Cspnet: A new backbone that can enhance learning capability of cnn,” 2020, pp. 390–391. [Online]. Available:
https://openaccess.thecvf.com/content_CVPRW_2020/html/w28/Wang_
CSPNet_A_New_Backbone_That_Can_Enhance_Learning_Capability_
of_CVPRW_2020_paper
[64] S. Liu, Y. Liang, and A. Gitter, “Loss-balanced task weighting to reduce
negative transfer in multi-task learning,” Proceedings of the AAAI Conference
on Artificial Intelligence, vol. 33, pp. 9977–9978, 2019.
[65] G. Wang, H. Li, Q. Xiao, P. Yu, Z. Ding, Z. Wang, and S. Xie, “Fighting
against forest fire: A lightweight real-time detection approach for forest
fire based on synthetic images,” Expert Systems with Applications, pp.
125 620–125 620, 11 2024.
붙임. 앙상블 구조 설명
|
앙상블(Ensemble) 구조란, 여러 개의 모델(혹은 알고리즘)을 결합하여 하나의 문제를 해결하는 방식입니다. 머신러닝과 딥러닝 분야에서 자주 사용되며, 개별 모델보다 더 높은 정확도와 안정성을 얻을 수 있다는 장점이 있습니다.
앙상블 구조의 개념
대표적인 앙상블 방법
앙상블의 장점
앙상블 구조의 예시
앙상블 구조는 여러 모델의 예측을 결합해 성능을 높이는 기법으로, 머신러닝과 딥러닝의 다양한 분야에서 널리 활용되고 있습니다. |
'人工智能' 카테고리의 다른 글
| ProRL: Prolonged Reinforcement Learning ExpandsReasoning Boundaries in Large Language Models (2) | 2025.06.06 |
|---|---|
| Learning to Reason without External Rewards (1) | 2025.06.06 |
| Potential Attack Surfaces in Agent2Agent (A2A) Protocol (0) | 2025.06.03 |
| [paper] Building A Secure Agentic AI Application Leveraging Google’s A2A Protocol (1) | 2025.06.01 |
| The State of LLM Reasoning Model Inference (1) | 2025.06.01 |


